|

Why your Customer Satisfaction Score maybe wildly inaccurate?
Humans are rarely objective and consistent when it comes to understanding the definition of a scale and rating.
Hence paradoxically one-scale-for-all CSATs introduces too much subjective judgement leading to erroneous interpretations. In reality a far more nuanced approach will be to collect authentic emotions and interpret them with AI/ML trained to accept large scale and diverse inputs.
CSAT or Customer Satisfaction Score is one of the most frequently used method to determine if a customer is satisfied with your product or service. It’s reliability comes from its simplicity of rating.
Typically, in a CSAT survey, you will find short and easy questions with numeric answers to measure satisfaction objectively. Alex Birkett, a graduate of the University of Wisconsin-Madison and an expert in growth marketing, sums it up precisely – “It is one of the most straightforward ways to measure customer satisfaction, and it is obtained by asking a simple question, such as ‘How satisfied were you with your experience?’ To answer, there’s a corresponding survey scale, which can be 1 – 3, 1 – 5, or 1 – 10.”
This simplicity of implementation makes CSAT, the obvious yardstick for customer success teams to assess their effectiveness.
Challenges with this approach
1. Recency Effect
The most obvious problem with the CSAT is that it only measures short term sentiments. Over the years, numerous psychological studies have proven that we rate an experience based on our immediate impulse but that assessment may not hold true after the impulse fades away. Hence our cognitive biases almost guarantee that we input most rating numbers at checkout counters based on the payment experience and not the whole buying journey. The longer the selling journey, the less the CSAT score reflects true emotions and only last 10% impulse.
2. The Objectivity Trap
Since 2000, Behavioural Science has confirmed scientifically something many marketers have long suspected – that consumers cannot always accurately describe their motivations or predict what factors might be decisive in influencing their buying behaviour. In the Objectivity Trap, Rory Sutherland of the Ogilvy Institute explains that Social Cohesion, Contextual Reading, Recency Effect & Primacy Effect are among the many psychological factors that make us rate an experience vs. objective facts. Hence to put it simply rating scales are fundamentally ineffective and creates an illusion of objectivity when it comes to rating experiences.
3. Negativity Bias
In today’s world we type 20 times more than 20 years back on an average. Hence our brain tends to classify any brand related typing as non essential unless we have extreme experiences. Study after study shows that over 70% of people who write feedback are within the 15%- 20% minority who have had negative experience with a brand. This leads to strong negativity bias of insights derived from CSAT and businesses are often scrambling to solve the 10% wrong instead focusing to double down on the 90% right.

Reversing the paradigm
So what if, instead of collecting lousy human ratings, we flipped the model and collected authentic emotions and categorize them?
“We will keep getting narrow subjective answers if we only use “satisfaction” as a measure”, says Jared Spool, co-founder and CEO of “Maker of Awesomeness” and expert in user experience.
“Instead”, he says, “I’m going to give you a list of attitudinal words … [and ] I want to see if you can pick out the one that’s a little different than the rest. I’ve got ‘delightful,’ ‘amazing,’ ‘awesome,’ ‘excellent,’ ‘remarkable,’ ‘incredible,’ and ‘satisfactory.’ Which word is different from the others? …Yes, satisfactory. Why is that word different? Well, if we were talking about a restaurant, a restaurant we loved, would we say, ‘Wow, that was incredibly satisfactory?”. Satisfactory in this context stands out as it implies that you created for the customer an average experience. And if the customer chooses that word it definitely shows that her or his top of the mind association with your eatery is that it is a mediocre place. That data point is far more revealing in predicting their enthusiasm about a repeat visit than taking a random number on a scale without a benchmark to compare against.
Designing amazing open ended CSAT
As interesting Jared’s experiment is, it still suffers from designer’s bias in picking the initial words. Fortunately modern technology allows us to be far bolder and design completely open ended CSAT mechanisms.
1. Open Ended Questions
Start your CSAT by asking one or two open ended questions without any leading hint? So ‘How was the dinner?’ is better to extract true opinion than ‘Did you love our dinner?’ where you are implicitly signalling that you want to hear that the diner enjoyed the experience. The diner will rate you high but because her true opinion has not been heard, will subconsciously assume you are NOT interested in her opinion, lowering your brand value and chance for a repeat visit.
2. Avoid Backfire Effect
Closely linked to point 1 above, if your survey gives too many implicit hints to rate you well, it will lead to backfire effect, where the more you try to convince the more the audience get determined that something is fishy, confirming their biases. Backfire effect is responsible for hardening of opinions and much polarization in the modern world on any sensitive topic.
3. Avoid Vanity Metrics
Surveys often succumb to backfire effect when Customer Success teams try to put too many implicit signals to rate them well. Avoid surveys becoming marketing tools with 100% ‘Green’ input for vanity whereas the uncomfortable flaws are not discovered leading to customer attrition in the long run.
4. Focus on Qualitative Data
Human beings are far more consistent when describing a scene with adjectives than ratings. Hence collect detailed feedback with adjectives and then try to extract sense out of them manually or with the help of AI/ML.
5. 30 Second design
Good surveys are short and fit within 1 screen and 2 scrolls of a standard iPhone or Android Phone taking at the maximum 30 seconds. Low barrier to give feedback increases response rate by 250 – 300%
How to improve your Surveys?
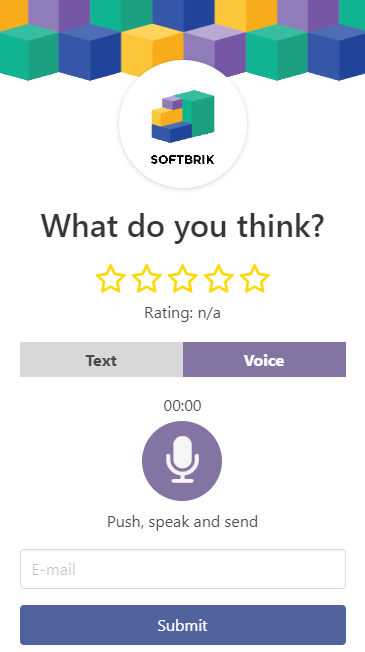
In Softbrik, we use the power of browser based Voice-to-Text to help teams create truly open ended surveys.
Your team can design voice feedback forms that are shared with your customers throughout their life journey like pre-sales, usage feedback, support and re-purchase. The forms are shared as either QR Codes or Web-links on websites and email. Customers just click or scan and talk in 22 languages. As talking is easier than typing we increase response rates by up to 500% and in 10 seconds capture 5 times more information than written text.
Our Machine Learning transcribes the voice to text, identifying critical contexts much deeper than just ratings from open ended customer responses. Additionally it translates the feedback to the team’s common language, accommodates for minor variations in accents, tones and phrasing by languages.
The feedback are finally grouped by tags with emotional analysis for either quick bulk response or deeper structural solutions.